- Published on
LeetCode SQL Problem Solving Questions With Solutions

175. Combine Two Tables | Easy | LeetCode
Table: Person
Table: Address
Write a SQL query for a report that provides the following information for each person in the Person table, regardless if there is an address for each of those people:
Solution
176. Second Highest Salary | Easy | LeetCode
Write a SQL query to get the second highest salary from the Employee table.
For example, given the above Employee table, the query should return 200 as the second highest salary. If there is no second highest salary, then the query should return null.
Solution
177. Nth Highest Salary | Medium | LeetCode
Write a SQL query to get the nth highest salary from the Employee table.
For example, given the above Employee table, the nth highest salary where n = 2 is 200. If there is no nth highest salary, then the query should return null.
Solution
178. Rank Scores | Medium | LeetCode
Write a SQL query to rank scores. If there is a tie between two scores, both should have the same ranking. Note that after a tie, the next ranking number should be the next consecutive integer value. In other words, there should be no "holes" between ranks.
For example, given the above Scores table, your query should generate the following report (order by highest score):
Important Note: For MySQL solutions, to escape reserved words used as column names, you can use an apostrophe before and after the keyword. For example Rank.
Solution
180. Consecutive Numbers | Medium | LeetCode
Table: Logs
Write an SQL query to find all numbers that appear at least three times consecutively.
Return the result table in any order.
The query result format is in the following example:
Solution
181. Employees Earning More Than Their Managers | Easy | LeetCode
The Employee table holds all employees including their managers. Every employee has an Id, and there is also a column for the manager Id.
Given the Employee table, write a SQL query that finds out employees who earn more than their managers. For the above table, Joe is the only employee who earns more than his manager.
Solution
182. Duplicate Emails | Easy | LeetCode
Write a SQL query to find all duplicate emails in a table named Person.
For example, your query should return the following for the above table:
Note: All emails are in lowercase.
Solution
183. Customers Who Never Order | Easy | LeetCode
Suppose that a website contains two tables, the Customers table and the Orders table. Write a SQL query to find all customers who never order anything.
Table: Customers.
Table: Orders.
Using the above tables as example, return the following:
Solution
184. Department Highest Salary | Medium | LeetCode
The Employee table holds all employees. Every employee has an Id, a salary, and there is also a column for the department Id.
The Department table holds all departments of the company.
Write a SQL query to find employees who have the highest salary in each of the departments. For the above tables, your SQL query should return the following rows (order of rows does not matter).
Explanation:
Max and Jim both have the highest salary in the IT department and Henry has the highest salary in the Sales department.
Solution
185. Department Top Three Salaries | Hard | LeetCode
The Employee table holds all employees. Every employee has an Id, and there is also a column for the department Id.
The Department table holds all departments of the company.
Write a SQL query to find employees who earn the top three salaries in each of the department. For the above tables, your SQL query should return the following rows (order of rows does not matter).
Explanation:
In IT department, Max earns the highest salary, both Randy and Joe earn the second highest salary, and Will earns the third highest salary. There are only two employees in the Sales department, Henry earns the highest salary while Sam earns the second highest salary.
Solution
196. Delete Duplicate Emails | Easy | LeetCode
Write a SQL query to delete all duplicate email entries in a table named Person, keeping only unique emails based on its smallest Id.
Id is the primary key column for this table. For example, after running your query, the above Person table should have the following rows:
Note:
Your output is the whole Person table after executing your sql. Use delete statement.
Solution
197. Rising Temperature | Easy | LeetCode
Table: Weather
Write an SQL query to find all dates' id with higher temperature compared to its previous dates (yesterday).
Return the result table in any order.
The query result format is in the following example:
Solution
262. Trips and Users | Hard | LeetCode
Table: Trips
Table: Users
Write a SQL query to find the cancellation rate of requests with unbanned users (both client and driver must not be banned) each day between "2013-10-01" and "2013-10-03".
The cancellation rate is computed by dividing the number of canceled (by client or driver) requests with unbanned users by the total number of requests with unbanned users on that day.
Return the result table in any order. Round Cancellation Rate to two decimal points.
The query result format is in the following example:
Solution
511. Game Play Analysis I | Easy | 🔒 LeetCode
Table: Activity
Write an SQL query that reports the first login date for each player.
The query result format is in the following example:
Solution
512. Game Play Analysis II | Easy | 🔒 LeetCode
Table: Activity
Write a SQL query that reports the device that is first logged in for each player.
The query result format is in the following example:
Solution
534. Game Play Analysis III | Medium | 🔒 LeetCode
Table: Activity
Write an SQL query that reports for each player and date, how many games played so far by the player. That is, the total number of games played by the player until that date. Check the example for clarity.
The query result format is in the following example:
Solution
550. Game Play Analysis IV | Medium | 🔒 LeetCode
Table: Activity
Write an SQL query that reports the fraction of players that logged in again on the day after the day they first logged in, rounded to 2 decimal places. In other words, you need to count the number of players that logged in for at least two consecutive days starting from their first login date, then divide that number by the total number of players.
The query result format is in the following example:
Solution
569. Median Employee Salary | Hard | 🔒 LeetCode
The Employee table holds all employees. The employee table has three columns: Employee Id, Company Name, and Salary.
Write a SQL query to find the median salary of each company. Bonus points if you can solve it without using any built-in SQL functions.
Solution
570. Managers with at Least 5 Direct Reports | Medium | 🔒 LeetCode
The Employee table holds all employees including their managers. Every employee has an Id, and there is also a column for the manager Id.
Given the Employee table, write a SQL query that finds out managers with at least 5 direct report. For the above table, your SQL query should return:
Note: No one would report to himself.
Solution
571. Find Median Given Frequency of Numbers | 🔒 LeetCode
The Numbers table keeps the value of number and its frequency.
In this table, the numbers are 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 3, so the median is (0 + 0) / 2 = 0.
Write a query to find the median of all numbers and name the result as median.
Solution
574. Winning Candidate | Medium | 🔒 LeetCode
Table: Candidate
Table: Vote
id is the auto-increment primary key, CandidateId is the id appeared in Candidate table. Write a sql to find the name of the winning candidate, the above example will return the winner B.
Notes: You may assume there is no tie, in other words there will be at most one winning candidate.
Solution
577. Employee Bonus | Easy | 🔒 LeetCode
Select all employee’s name and bonus whose bonus is < 1000.
Table:Employee
Table: Bonus
Example ouput:
Solution
578. Get Highest Answer Rate Question | Medium | 🔒 LeetCode
Get the highest answer rate question from a table survey_log with these columns: uid, action, question_id, answer_id, q_num, timestamp.
uid means user id; action has these kind of values: “show”, “answer”, “skip”; answer_id is not null when action column is “answer”, while is null for “show” and “skip”; q_num is the numeral order of the question in current session.
Write a sql query to identify the question which has the highest answer rate.
Example: Input:
Output:
Explanation: question 285 has answer rate 1/1, while question 369 has 0/1 answer rate, so output 285.
Note: The highest answer rate meaning is: answer number’s ratio in show number in the same question.
Solution
579. Find Cumulative Salary of an Employee | Hard | 🔒 LeetCode
The Employee table holds the salary information in a year.
Write a SQL to get the cumulative sum of an employee’s salary over a period of 3 months but exclude the most recent month.
The result should be displayed by ‘Id’ ascending, and then by ‘Month’ descending.
Example Input
Output
Explanation Employee ‘1’ has 3 salary records for the following 3 months except the most recent month ‘4’: salary 40 for month ‘3’, 30 for month ‘2’ and 20 for month ‘1’ So the cumulative sum of salary of this employee over 3 months is 90(40+30+20), 50(30+20) and 20 respectively.
Employee ‘2’ only has one salary record (month ‘1’) except its most recent month ‘2’.
Employ ‘3’ has two salary records except its most recent pay month ‘4’: month ‘3’ with 60 and month ‘2’ with 40. So the cumulative salary is as following.
Solution
580. Count Student Number in Departments | Medium | 🔒 LeetCode
A university uses 2 data tables, student and department, to store data about its students and the departments associated with each major.
Write a query to print the respective department name and number of students majoring in each department for all departments in the department table (even ones with no current students).
Sort your results by descending number of students; if two or more departments have the same number of students, then sort those departments alphabetically by department name.
The student is described as follow:
where student_id is the student’s ID number, student_name is the student’s name, gender is their gender, and dept_id is the department ID associated with their declared major.
And the department table is described as below:
where dept_id is the department’s ID number and dept_name is the department name.
Here is an example input: student table:
department table:
The Output should be:
Solution
584. Find Customer Referee | Easy | 🔒 LeetCode
Given a table customer holding customers information and the referee.
Write a query to return the list of customers NOT referred by the person with id ‘2’.
For the sample data above, the result is:
Solution
585. Investments in 2016 | Medium | 🔒 LeetCode
Write a query to print the sum of all total investment values in 2016 (TIV_2016), to a scale of 2 decimal places, for all policy holders who meet the following criteria:
- Have the same TIV_2015 value as one or more other policyholders.
- Are not located in the same city as any other policyholder (i.e.: the (latitude, longitude) attribute pairs must be unique). Input Format: The insurance table is described as follows:
where PID is the policyholder’s policy ID, TIV_2015 is the total investment value in 2015, TIV_2016 is the total investment value in 2016, LAT is the latitude of the policy holder’s city, and LON is the longitude of the policy holder’s city.
Sample Input
Sample Output
Explanation
Solution
586. Customer Placing the Largest Number of Orders | Easy | 🔒 LeetCode
Query the customer_number from the orders table for the customer who has placed the largest number of orders.
It is guaranteed that exactly one customer will have placed more orders than any other customer.
The orders table is defined as follows:
Sample Input
Sample Output
Explanation
Solution
595. Big Countries | Easy | LeetCode
There is a table World
A country is big if it has an area of bigger than 3 million square km or a population of more than 25 million.
Write a SQL solution to output big countries' name, population and area.
For example, according to the above table, we should output:
Solution
596. Classes More Than 5 Students | Easy | LeetCode
There is a table courses with columns: student and class
Please list out all classes which have more than or equal to 5 students.
For example, the table:
Should output:
Solution
597. Friend Requests I: Overall Acceptance Rate | Easy | 🔒 LeetCode
In social network like Facebook or Twitter, people send friend requests and accept others’ requests as well. Now given two tables as below: Table: friend_request
Table: request_accepted
Write a query to find the overall acceptance rate of requests rounded to 2 decimals, which is the number of acceptance divide the number of requests. For the sample data above, your query should return the following result.
Note:
The accepted requests are not necessarily from the table friend_request. In this case, you just need to simply count the total accepted requests (no matter whether they are in the original requests), and divide it by the number of requests to get the acceptance rate. It is possible that a sender sends multiple requests to the same receiver, and a request could be accepted more than once. In this case, the ‘duplicated’ requests or acceptances are only counted once. If there is no requests at all, you should return 0.00 as the accept_rate. Explanation: There are 4 unique accepted requests, and there are 5 requests in total. So the rate is 0.80.
Follow-up:
Can you write a query to return the accept rate but for every month? How about the cumulative accept rate for every day?
Solution
601. Human Traffic of Stadium | Hard | LeetCode
Table: Stadium
visit_date is the primary key for this table. Each row of this table contains the visit date and visit id to the stadium with the number of people during the visit. No two rows will have the same visit_date, and as the id increases, the dates increase as well.
Write an SQL query to display the records with three or more rows with consecutive id's, and the number of people is greater than or equal to 100 for each.
Return the result table ordered by visit_date in ascending order.
The query result format is in the following example.
Solution
602. Friend Requests II: Who Has the Most Friends | Medium | 🔒 LeetCode
In social network like Facebook or Twitter, people send friend requests and accept others’ requests as well. Table request_accepted holds the data of friend acceptance, while requester_id and accepter_id both are the id of a person.
Write a query to find the the people who has most friends and the most friends number. For the sample data above, the result is:
Note:
It is guaranteed there is only 1 people having the most friends. The friend request could only been accepted once, which mean there is no multiple records with the same requester_id and accepter_id value. Explanation: The person with id ‘3’ is a friend of people ‘1’, ‘2’ and ‘4’, so he has 3 friends in total, which is the most number than any others.
Follow-up: In the real world, multiple people could have the same most number of friends, can you find all these people in this case?
603. Consecutive Available Seats | Easy | 🔒 LeetCode
Several friends at a cinema ticket office would like to reserve consecutive available seats. Can you help to query all the consecutive available seats order by the seat_id using the following cinema table?
Your query should return the following result for the sample case above.
Note:
The seat_id is an auto increment int, and free is bool (‘1’ means free, and ‘0’ means occupied.). Consecutive available seats are more than 2(inclusive) seats consecutively available.
Solution
607.Sales Person | Easy | 🔒 LeetCode
Description
Given three tables: salesperson, company, orders. Output all the names in the table salesperson, who didn’t have sales to company ‘RED’.
Example Input
Table: salesperson
The table salesperson holds the salesperson information. Every salesperson has a sales_id and a name. Table: company
The table company holds the company information. Every company has a com_id and a name. Table: orders
The table orders holds the sales record information, salesperson and customer company are represented by sales_id and com_id. output
Explanation
According to order ‘3’ and ‘4’ in table orders, it is easy to tell only salesperson ‘John’ and ‘Alex’ have sales to company ‘RED’, so we need to output all the other names in table salesperson.
Solution
608. Tree Node | Medium | 🔒 LeetCode
Given a table tree, id is identifier of the tree node and p_id is its parent node’s id.
Each node in the tree can be one of three types:
Leaf: if the node is a leaf node. Root: if the node is the root of the tree. Inner: If the node is neither a leaf node nor a root node. Write a query to print the node id and the type of the node. Sort your output by the node id. The result for the above sample is:
Explanation
Node ‘1’ is root node, because its parent node is NULL and it has child node ‘2’ and ‘3’. Node ‘2’ is inner node, because it has parent node ‘1’ and child node ‘4’ and ‘5’. Node ‘3’, ‘4’ and ‘5’ is Leaf node, because they have parent node and they don’t have child node. And here is the image of the sample tree as below:
Note
If there is only one node on the tree, you only need to output its root attributes.
Solution
610. Triangle Judgement | Easy | 🔒 LeetCode
A pupil Tim gets homework to identify whether three line segments could possibly form a triangle. However, this assignment is very heavy because there are hundreds of records to calculate. Could you help Tim by writing a query to judge whether these three sides can form a triangle, assuming table triangle holds the length of the three sides x, y and z.
For the sample data above, your query should return the follow result:
Solution
612. Shortest Distance in a Plane | Medium | 🔒 LeetCode
Table point_2d holds the coordinates (x,y) of some unique points (more than two) in a plane. Write a query to find the shortest distance between these points rounded to 2 decimals.
The shortest distance is 1.00 from point (-1,-1) to (-1,2). So the output should be:
Note: The longest distance among all the points are less than 10000.
Solution
613. Shortest Distance in a Line | Easy | 🔒 LeetCode
Table point holds the x coordinate of some points on x-axis in a plane, which are all integers. Write a query to find the shortest distance between two points in these points.
The shortest distance is ‘1’ obviously, which is from point ‘-1’ to ‘0’. So the output is as below:
Note: Every point is unique, which means there is no duplicates in table point.
Follow-up: What if all these points have an id and are arranged from the left most to the right most of x axis?
Solution
614. Second Degree Follower | Medium | 🔒 LeetCode
In facebook, there is a follow table with two columns: followee, follower.
Please write a sql query to get the amount of each follower’s follower if he/she has one.
For example:
should output:
Explanation: Both B and D exist in the follower list, when as a followee, B’s follower is C and D, and D’s follower is E. A does not exist in follower list.
Note: Followee would not follow himself/herself in all cases. Please display the result in follower’s alphabet order.
Solution
615. Average Salary: Departments VS Company | Hard | 🔒 LeetCode
Given two tables as below, write a query to display the comparison result (higher/lower/same) of the average salary of employees in a department to the company’s average salary. Table: salary
The employee_id column refers to the employee_id in the following table employee.
So for the sample data above, the result is:
Explanation In March, the company’s average salary is (9000+6000+10000)/3 = 8333.33… The average salary for department ‘1’ is 9000, which is the salary of employee_id ‘1’ since there is only one employee in this department. So the comparison result is ‘higher’ since 9000 > 8333.33 obviously. The average salary of department ‘2’ is (6000 + 10000)/2 = 8000, which is the average of employee_id ‘2’ and ‘3’. So the comparison result is ‘lower’ since 8000 < 8333.33. With he same formula for the average salary comparison in February, the result is ‘same’ since both the department ‘1’ and ‘2’ have the same average salary with the company, which is 7000.
Solution
618. Students Report By Geography | Hard | 🔒 LeetCode
A U.S graduate school has students from Asia, Europe and America. The students’ location information are stored in table student as below.
Pivot the continent column in this table so that each name is sorted alphabetically and displayed underneath its corresponding continent. The output headers should be America, Asia and Europe respectively. It is guaranteed that the student number from America is no less than either Asia or Europe. For the sample input, the output is:
Follow-up: If it is unknown which continent has the most students, can you write a query to generate the student report?
Solution
619. Biggest Single Number | Easy | 🔒 LeetCode
Table number contains many numbers in column num including duplicated ones. Can you write a SQL query to find the biggest number, which only appears once.
For the sample data above, your query should return the following result:
Note: If there is no such number, just output null.
Solution
620. Not Boring Movies | Easy | LeetCode
X city opened a new cinema, many people would like to go to this cinema. The cinema also gives out a poster indicating the movies’ ratings and descriptions. Please write a SQL query to output movies with an odd numbered ID and a description that is not 'boring'. Order the result by rating.
For example, table cinema:
For the example above, the output should be:
Solution
626. Exchange Seats | Medium | LeetCode
Mary is a teacher in a middle school and she has a table seat storing students' names and their corresponding seat ids.
The column id is continuous increment.
Mary wants to change seats for the adjacent students.
Can you write a SQL query to output the result for Mary?
For the sample input, the output is:
Note:
If the number of students is odd, there is no need to change the last one's seat.
Solution
627. Swap Salary | LeetCode
Table: Salary
Write an SQL query to swap all 'f' and 'm' values (i.e., change all 'f' values to 'm' and vice versa) with a single update statement and no intermediate temp table(s).
Note that you must write a single update statement, DO NOT write any select statement for this problem.
The query result format is in the following example:
Solution
1045. Customers Who Bought All Products | Medium | 🔒 LeetCode
Table: Customer
product_key is a foreign key to Product table. Table: Product
Write an SQL query for a report that provides the customer ids from the Customer table that bought all the products in the Product table.
For example:
Solution
1050. Actors and Directors Who Cooperated At Least Three Times | Easy | 🔒 LeetCode
Table: ActorDirector
Write a SQL query for a report that provides the pairs (actor_id, director_id) where the actor have cooperated with the director at least 3 times.
Example:
Solution
1068. Product Sales Analysis I | Easy | 🔒 LeetCode
Table: Sales
Table: Product
Write an SQL query that reports all product names of the products in the Sales table along with their selling year and price.
For example:
Solution
1069. Product Sales Analysis II | Easy | 🔒 LeetCode
Table: Sales
Table: Product
Write an SQL query that reports the total quantity sold for every product id.
The query result format is in the following example:
Solution
1070. Product Sales Analysis III | Medium | 🔒 LeetCode
Table: Sales
Table: Product
Write an SQL query that selects the product id, year, quantity, and price for the first year of every product sold.
The query result format is in the following example:
Solution
1075. Project Employees I | Easy | 🔒 LeetCode
Table: Project
Table: Employee
Write an SQL query that reports the average experience years of all the employees for each project, rounded to 2 digits.
The query result format is in the following example:
Solution
1076. Project Employees II | Easy | 🔒 LeetCode
Table: Project
Table: Employee
Write an SQL query that reports all the projects that have the most employees.
The query result format is in the following example:
1077. Project Employees III | Medium | 🔒 LeetCode
Table: Project
Table: Employee
Write an SQL query that reports the most experienced employees in each project. In case of a tie, report all employees with the maximum number of experience years.
The query result format is in the following example:
Solution
1082. Sales Analysis I | Easy | 🔒 LeetCode
Table: Product
Table: Sales
Write an SQL query that reports the best seller by total sales price, If there is a tie, report them all.
The query result format is in the following example:
Solution
1083. Sales Analysis II | Easy | 🔒 LeetCode
Table: Product
Table: Sales
Write an SQL query that reports the buyers who have bought S8 but not iPhone. Note that S8 and iPhone are products present in the Product table.
The query result format is in the following example:
Solution
1084. Sales Analysis III | Easy | 🔒 LeetCode
Reports the products that were only sold in spring 2019. That is, between 2019-01-01 and 2019-03-31 inclusive. Select the product that were only sold in spring 2019.
Solution
1097. Game Play Analysis V | Hard | 🔒 LeetCode
We define the install date of a player to be the first login day of that player. We also define day 1 retention of some date X to be the number of players whose install date is X and they logged back in on the day right after X , divided by the number of players whose install date is X, rounded to 2 decimal places. Write an SQL query that reports for each install date, the number of players that installed the game on that day and the day 1 retention. The query result format is in the following example:
Solution
1098. Unpopular Books | Medium | 🔒 LeetCode
Table: Books
Table: Orders
Write an SQL query that reports the books that have sold less than 10 copies in the last year, excluding books that have been available for less than 1 month from today. Assume today is 2019-06-23.
The query result format is in the following example:
Solution
1107. New Users Daily Count | Medium | 🔒 LeetCode
Table: Traffic
Write an SQL query that reports for every date within at most 90 days from today, the number of users that logged in for the first time on that date. Assume today is 2019-06-30.
The query result format is in the following example:
Solution
1112. Highest Grade For Each Student | Medium | 🔒 LeetCode
Table: Enrollments
Write a SQL query to find the highest grade with its corresponding course for each student. In case of a tie, you should find the course with the smallest course_id. The output must be sorted by increasing student_id.
The query result format is in the following example:
Solution
1113.Reported Posts | Easy | 🔒 LeetCode
Table: Actions
Write an SQL query that reports the number of posts reported yesterday for each report reason. Assume today is 2019-07-05.
The query result format is in the following example:
Note that we only care about report reasons with non zero number of reports.
Solution
1126. Active Businesses | Medium | 🔒 LeetCode
Table: Events
Write an SQL query to find all active businesses.
An active business is a business that has more than one event type with occurences greater than the average occurences of that event type among all businesses.
The query result format is in the following example:
Solution
1127. User Purchase Platform | Hard | 🔒 LeetCode
Table: Spending
Write an SQL query to find the total number of users and the total amount spent using mobile only, desktop only and both mobile and desktop together for each date.
The query result format is in the following example:
Solution
1132. Reported Posts II | Medium | 🔒 LeetCode
Table: Actions
Table: Removals
Write an SQL query to find the average for daily percentage of posts that got removed after being reported as spam, rounded to 2 decimal places.
The query result format is in the following example:
Solution
1141. User Activity for the Past 30 Days I | Easy | 🔒 LeetCode
Table: Activity
Write an SQL query to find the daily active user count for a period of 30 days ending 2019-07-27 inclusively. A user was active on some day if he/she made at least one activity on that day.
The query result format is in the following example:
Solution
1142. User Activity for the Past 30 Days II | Easy | 🔒 LeetCode
Table: Activity
Write an SQL query to find the average number of sessions per user for a period of 30 days ending 2019-07-27 inclusively, rounded to 2 decimal places. The sessions we want to count for a user are those with at least one activity in that time period.
The query result format is in the following example:
Solution
1148. Article Views I | Easy | 🔒 LeetCode
Table: Views
Write an SQL query to find all the authors that viewed at least one of their own articles, sorted in ascending order by their id.
The query result format is in the following example:
Solution
1149. Article Views II | Medium | 🔒 LeetCode
Table: Views
Write an SQL query to find all the people who viewed more than one article on the same date, sorted in ascending order by their id.
The query result format is in the following example:
Solution
1158. Market Analysis I | Medium | 🔒 LeetCode
Table: Users
Table: Orders
Table: Items
Write an SQL query to find for each user, the join date and the number of orders they made as a buyer in 2019.
The query result format is in the following example:
Solution
1159. Market Analysis II | Hard | 🔒 LeetCode
Table: Users
Table: Orders
Table: Items
Write an SQL query to find for each user, whether the brand of the second item (by date) they sold is their favorite brand. If a user sold less than two items, report the answer for that user as no.
It is guaranteed that no seller sold more than one item on a day.
The query result format is in the following example:
Solution
1164. Product Price at a Given Date | Medium | 🔒 LeetCode
Table: Products
Write an SQL query to find the prices of all products on 2019-08-16. Assume the price of all products before any change is 10.
The query result format is in the following example:
Solution
1173. Immediate Food Delivery I | Easy | 🔒 LeetCode
Table: Delivery
If the preferred delivery date of the customer is the same as the order date then the order is called immediate otherwise it's called scheduled.
Write an SQL query to find the percentage of immediate orders in the table, rounded to 2 decimal places.
The query result format is in the following example:
Solution
1174. Immediate Food Delivery II | Medium | 🔒 LeetCode
Table: Delivery
If the preferred delivery date of the customer is the same as the order date then the order is called immediate otherwise it's called scheduled.
The first order of a customer is the order with the earliest order date that customer made. It is guaranteed that a customer has exactly one first order.
Write an SQL query to find the percentage of immediate orders in the first orders of all customers, rounded to 2 decimal places.
The query result format is in the following example:
Solution
1179. Reformat Department Table | Easy | LeetCode
Table: Department
Write an SQL query to reformat the table such that there is a department id column and a revenue column for each month.
The query result format is in the following example:
Solution
1193. Monthly Transactions I | Medium | 🔒 LeetCode
Table: Transactions
Write an SQL query to find for each month and country, the number of transactions and their total amount, the number of approved transactions and their total amount.
The query result format is in the following example:
Solution
1194. Tournament Winners | Hard | 🔒 LeetCode
Table: Players
Table: Matches
The winner in each group is the player who scored the maximum total points within the group. In the case of a tie, the lowest player_id wins.
Write an SQL query to find the winner in each group.
The query result format is in the following example:
Solution
1204. Last Person to Fit in the Elevator | Medium | 🔒 LeetCode
Table: Queue
The maximum weight the elevator can hold is 1000.
Write an SQL query to find the person_name of the last person who will fit in the elevator without exceeding the weight limit. It is guaranteed that the person who is first in the queue can fit in the elevator.
The query result format is in the following example:
Solution
1205. Monthly Transactions II | Medium | 🔒 LeetCode
Table: Transactions
Table: Chargebacks
Write an SQL query to find for each month and country, the number of approved transactions and their total amount, the number of chargebacks and their total amount.
Note: In your query, given the month and country, ignore rows with all zeros.
The query result format is in the following example:
Solution
1211. Queries Quality and Percentage | Easy | 🔒 LeetCode
Table: Queries
We define query quality as:
- The average of the ratio between query rating and its position.
We also define poor query percentage as:
- The percentage of all queries with rating less than 3.
Write an SQL query to find each query_name, the quality and poor_query_percentage.
Both quality and poor_query_percentage should be rounded to 2 decimal places.
The query result format is in the following example:
Solution
1212. Team Scores in Football Tournament | Medium | 🔒 LeetCode
Table: Teams
Table: Matches
You would like to compute the scores of all teams after all matches. Points are awarded as follows:
A team receives three points if they win a match (Score strictly more goals than the opponent team).
A team receives one point if they draw a match (Same number of goals as the opponent team).
A team receives no points if they lose a match (Score less goals than the opponent team).
Write an SQL query that selects the team_id, team_name and num_points of each team in the tournament after all described matches. Result table should be ordered by num_points (decreasing order). In case of a tie, order the records by team_id (increasing order).
The query result format is in the following example:
Solution
1225. Report Contiguous Dates | Hard | 🔒 LeetCode
Table: Failed
Table: Succeeded
A system is running one task every day. Every task is independent of the previous tasks. The tasks can fail or succeed.
Write an SQL query to generate a report of period_state for each continuous interval of days in the period from 2019-01-01 to 2019-12-31.
period_state is 'failed' if tasks in this interval failed or 'succeeded' if tasks in this interval succeeded. Interval of days are retrieved as start_date and end_date.
Order result by start_date.
The query result format is in the following example:
Solution
1241. Number of Comments per Post | Easy | 🔒 LeetCode
Table: Submissions
Write an SQL query to find number of comments per each post.
Result table should contain post_id and its corresponding number_of_comments, and must be sorted by post_id in ascending order.
Submissions may contain duplicate comments. You should count the number of unique comments per post.
Submissions may contain duplicate posts. You should treat them as one post.
The query result format is in the following example:
Solution
1251. Average Selling Price | Easy | 🔒 LeetCode
Table: Prices
Table: UnitsSold
Write an SQL query to find the average selling price for each product.
average_price should be rounded to 2 decimal places.
The query result format is in the following example:
Solution
1264. Page Recommendations | Medium | 🔒 LeetCode
Table: Friendship
Table: Likes
Write an SQL query to recommend pages to the user with user_id = 1 using the pages that your friends liked. It should not recommend pages you already liked.
Return result table in any order without duplicates.
The query result format is in the following example:
Solution
1270. All People Report to the Given Manager | Medium | 🔒 LeetCode
Table: Employees
Write an SQL query to find employee_id of all employees that directly or indirectly report their work to the head of the company.
The indirect relation between managers will not exceed 3 managers as the company is small.
Return result table in any order without duplicates.
The query result format is in the following example:
Solution
1280. Students and Examinations| Easy | 🔒 LeetCode
Table: Students
Table: Subjects
Table: Examinations
Write an SQL query to find the number of times each student attended each exam.
Order the result table by student_id and subject_name.
The query result format is in the following example:
Solution
1285. Find the Start and End Number of Continuous Ranges | Medium | 🔒 LeetCode
Table: Logs
Since some IDs have been removed from Logs. Write an SQL query to find the start and end number of continuous ranges in table Logs.
Order the result table by start_id.
The query result format is in the following example:
Solution
1294. Weather Type in Each Country | Easy | 🔒 LeetCode
Table: Countries
Table: Weather
Write an SQL query to find the type of weather in each country for November 2019.
The type of weather is Cold if the average weather_state is less than or equal 15, Hot if the average weather_state is greater than or equal 25 and Warm otherwise.
Return result table in any order.
The query result format is in the following example:
Solution
1303. Find the Team Size | Easy | 🔒 LeetCode
Table: Employee
Write an SQL query to find the team size of each of the employees.
Return result table in any order.
The query result format is in the following example:
Solution
1308. Running Total for Different Genders | Medium | 🔒 LeetCode
Table: Scores
Write an SQL query to find the total score for each gender at each day.
Order the result table by gender and day
The query result format is in the following example:
Solution
1321. Restaurant Growth | Medium | 🔒 LeetCode
Table: Customer
You are the restaurant owner and you want to analyze a possible expansion (there will be at least one customer every day).
Write an SQL query to compute moving average of how much customer paid in a 7 days window (current day + 6 days before) .
The query result format is in the following example:
Return result table ordered by visited_on.
average_amount should be rounded to 2 decimal places, all dates are in the format ('YYYY-MM-DD').
Solution
1322. Ads Performance | Easy | 🔒 LeetCode
Table: Ads
A company is running Ads and wants to calculate the performance of each Ad.
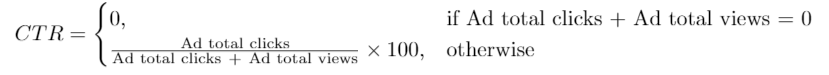
Round ctr to 2 decimal points. Order the result table by ctr in descending order and by ad_id in ascending order in case of a tie.
The query result format is in the following example:
Solution
1327. List the Products Ordered in a Period | Easy | 🔒 LeetCode
Table: Products
Table: Orders
Write an SQL query to get the names of products with greater than or equal to 100 units ordered in February 2020 and their amount.
Return result table in any order.
The query result format is in the following example:
Solution
1336. Number of Transactions per Visit | Hard | 🔒 LeetCode
Table: Visits
Table: Transactions
A bank wants to draw a chart of the number of transactions bank visitors did in one visit to the bank and the corresponding number of visitors who have done this number of transaction in one visit.
Write an SQL query to find how many users visited the bank and didn't do any transactions, how many visited the bank and did one transaction and so on.
The result table will contain two columns:
transactions_countwhich is the number of transactions done in one visit.visits_countwhich is the corresponding number of users who did transactions_count in one visit to the bank.transactions_countshould take all values from0tomax(transactions_count)done by one or more users.
Order the result table by transactions_count.
The query result format is in the following example:
The chart drawn for this example is as follows:
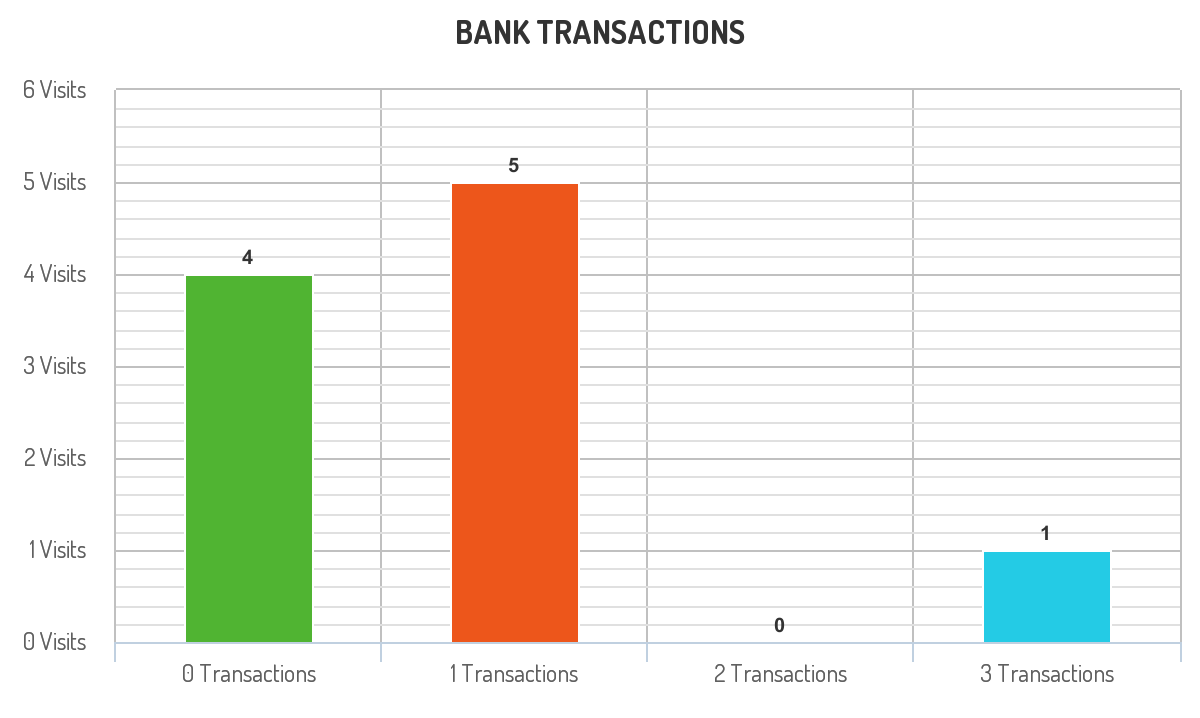
Solution
1341. Movie Rating | Medium | 🔒 LeetCode
Table: Movies
Table: Users
Table: Movie_Rating
Write the following SQL query:
Find the name of the user who has rated the greatest number of the movies.
In case of a tie, return lexicographically smaller user name.Find the movie name with the highest average rating in February 2020.
In case of a tie, return lexicographically smaller movie name..
Query is returned in 2 rows, the query result format is in the following example:
Solution
1350. Students With Invalid Departments | Easy | 🔒 LeetCode
Table: Departments
Table: Students
Write an SQL query to find the id and the name of all students who are enrolled in departments that no longer exists.
Return the result table in any order.
The query result format is in the following example:
Solution
1355. Activity Participants | Medium | 🔒 LeetCode
Table: Friends
Table: Activities
Write an SQL query to find the names of all the activities with neither maximum, nor minimum number of participants.
Return the result table in any order. Each activity in table Activities is performed by any person in the table Friends.
The query result format is in the following example:
Solution
1364. Number of Trusted Contacts of a Customer | Medium | 🔒 LeetCode
Table: Customers
Table: Contacts
Table: Invoices
Write an SQL query to find the following for each invoice_id:
- customer_name: The name of the customer the invoice is related to.
- price: The price of the invoice.
- contacts_cnt: The number of contacts related to the customer.
- trusted_contacts_cnt: The number of contacts related to the customer and at the same time they are customers to the shop. (i.e His/Her email exists in the Customers table.) Order the result table by invoice_id.
The query result format is in the following example:
Solution
1369. Get the Second Most Recent Activity | Hard | 🔒 LeetCode
Table: UserActivity
Write an SQL query to show the second most recent activity of each user.
If the user only has one activity, return that one.
A user can't perform more than one activity at the same time. Return the result table in any order.
The query result format is in the following example:
Solution
1378. Replace Employee ID With The Unique Identifier | Easy | 🔒 LeetCode
Table: Employees
Table: EmployeeUNI
Write an SQL query to show the unique ID of each user, If a user doesn't have a unique ID replace just show null.
Return the result table in any order.
The query result format is in the following example:
Solution
1384. Total Sales Amount by Year | Hard | 🔒 LeetCode
Table: Product
+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | product_name | varchar | +---------------+---------+ product_id is the primary key for this table. product_name is the name of the product.
Table: Sales
Write an SQL query to report the Total sales amount of each item for each year, with corresponding product name, product_id, product_name and report_year.
Dates of the sales years are between 2018 to 2020. Return the result table ordered by product_id and report_year.
The query result format is in the following example:
Solution
1393. Capital Gain/Loss | Medium | 🔒 LeetCode
Table: Stocks
Write an SQL query to report the Capital gain/loss for each stock.
The capital gain/loss of a stock is total gain or loss after buying and selling the stock one or many times.
Return the result table in any order.
The query result format is in the following example:
Solution
1398. Customers Who Bought Products A and B but Not C | Medium | 🔒 LeetCode
Table: Customers
Table: Orders
Write an SQL query to report the customer_id and customer_name of customers who bought products "A", "B" but did not buy the product "C" since we want to recommend them buy this product.
Return the result table ordered by customer_id.
The query result format is in the following example.
Solution
1407. Top Travellers | Easy | 🔒 LeetCode
Table: Users
Table: Rides
Write an SQL query to report the distance travelled by each user.
Return the result table ordered by travelled_distance in descending order, if two or more users travelled the same distance, order them by their name in ascending order.
The query result format is in the following example.
Solution
1412. Find the Quiet Students in All Exams | Hard | 🔒 LeetCode
Table: Student
Table: Exam
A "quite" student is the one who took at least one exam and didn't score neither the high score nor the low score.
Write an SQL query to report the students (student_id, student_name) being "quiet" in ALL exams.
Don't return the student who has never taken any exam. Return the result table ordered by student_id.
The query result format is in the following example.
Solution
1421. NPV Queries | Medium | 🔒 LeetCode
Table: NPV
Table: Queries
Write an SQL query to find the npv of all each query of queries table.
Return the result table in any order.
The query result format is in the following example:
Solution
1435. Create a Session Bar Chart | Easy | 🔒 LeetCode
Table: Sessions
You want to know how long a user visits your application. You decided to create bins of "[0-5>", "[5-10>", "[10-15>" and "15 minutes or more" and count the number of sessions on it.
Write an SQL query to report the (bin, total) in any order.
Solution
1440. Evaluate Boolean Expression | Medium | 🔒 LeetCode
Table Variables:
Table Expressions:
Write an SQL query to evaluate the boolean expressions in Expressions table.
Return the result table in any order.
The query result format is in the following example.
Solution
1445. Apples & Oranges | Medium | 🔒 LeetCode
Table: Sales
Write an SQL query to report the difference between number of apples and oranges sold each day.
Return the result table ordered by sale_date in format ('YYYY-MM-DD').
The query result format is in the following example:
Solution
1454. Active Users | Medium | 🔒 LeetCode
Table Accounts:
Table Logins:
Write an SQL query to find the id and the name of active users.
Active users are those who logged in to their accounts for 5 or more consecutive days.
Return the result table ordered by the id.
The query result format is in the following example:
Follow up question: Can you write a general solution if the active users are those who logged in to their accounts for n or more consecutive days?
Solution
1459. Rectangles Area | Medium | 🔒 LeetCode
Table: Points
Write an SQL query to report of all possible rectangles which can be formed by any two points of the table.
Each row in the result contains three columns (p1, p2, area) where:
- p1 and p2 are the id of two opposite corners of a rectangle and p1 < p2.
- Area of this rectangle is represented by the column area. Report the query in descending order by area in case of tie in ascending order by p1 and p2.
Solution
1468. Calculate Salaries | Medium | 🔒 LeetCode
Table Salaries:
Write an SQL query to find the salaries of the employees after applying taxes.
The tax rate is calculated for each company based on the following criteria:
- 0% If the max salary of any employee in the company is less than 1000$.
- 24% If the max salary of any employee in the company is in the range [1000, 10000] inclusive.
- 49% If the max salary of any employee in the company is greater than 10000$.
Return the result table in any order. Round the salary to the nearest integer.
The query result format is in the following example:
Solution
1479. Sales by Day of the Week | Hard | 🔒 LeetCode
Table: Orders
Table: Items
You are the business owner and would like to obtain a sales report for category items and day of the week.
Write an SQL query to report how many units in each category have been ordered on each day of the week.
Return the result table ordered by category.
The query result format is in the following example:
Solution
1484. Group Sold Products By The Date | Easy | 🔒 LeetCode
Table Activities:
Write an SQL query to find for each date, the number of distinct products sold and their names.
The sold-products names for each date should be sorted lexicographically.
Return the result table ordered by sell_date.
The query result format is in the following example.
Solution
1495. Friendly Movies Streamed Last Month | Easy | 🔒 LeetCode
Table: TVProgram
Table: Content
Write an SQL query to report the distinct titles of the kid-friendly movies streamed in June 2020.
Return the result table in any order.
The query result format is in the following example.
Solution
1501. Countries You Can Safely Invest In | Medium | 🔒 LeetCode
Table Person:
Table Country:
Table Calls:
Write an SQL query to find the countries where this company can invest.
Return the result table in any order.
The query result format is in the following example.
Solution
1511. Customer Order Frequency | Easy | 🔒 LeetCode
Table: Customers
Table: Product
Table: Orders
Write an SQL query to report the customer_id and customer_name of customers who have spent at least $100 in each month of June and July 2020.
Return the result table in any order.
The query result format is in the following example.
Solution
1517. Find Users With Valid E-Mails | Easy | 🔒 LeetCode
Table: Users
Write an SQL query to find the users who have valid emails.
A valid e-mail has a prefix name and a domain where:
- The prefix name is a string that may contain letters (upper or lower case), digits, underscore
'_', period'.'and/or dash'-'. The prefix name must start with a letter. - The domain is
'@leetcode.com'.
Return the result table in any order.
The query result format is in the following example.
Solution
1527. Patients With a Condition | Easy | 🔒 LeetCode
Table: Patients
Write an SQL query to report the patient_id, patient_name all conditions of patients who have Type I Diabetes. Type I Diabetes always starts with DIAB1 prefix
Return the result table in any order.
The query result format is in the following example.
Solution
1532. The Most Recent Three Orders | Medium | 🔒 LeetCode
Table: Customers
Table: Orders
Write an SQL query to find the most recent 3 orders of each user. If a user ordered less than 3 orders return all of their orders.
Return the result table sorted by customer_name in ascending order and in case of a tie by the customer_id in ascending order. If there still a tie, order them by the order_date in descending order.
The query result format is in the following example:
Solution
1543. Fix Product Name Format | Easy | 🔒 LeetCode
Table: Sales
Since table Sales was filled manually in the year 2000, product_name may contain leading and/or trailing white spaces, also they are case-insensitive.
Write an SQL query to report
product_namein lowercase without leading or trailing white spaces.sale_datein the format('YYYY-MM')totalthe number of times the product was sold in this month.
Return the result table ordered byproduct_namein ascending order, in case of a tie order it bysale_datein ascending order.
The query result format is in the following example.
Solution
1549. The Most Recent Orders for Each Product | Medium | 🔒 LeetCode
Table: Customers
Table: Orders
Table: Products
Write an SQL query to find the most recent order(s) of each product.
Return the result table sorted by product_name in ascending order and in case of a tie by the product_id in ascending order. If there still a tie, order them by the order_id in ascending order.
The query result format is in the following example:
Solution
1555. Bank Account Summary | Medium | 🔒 LeetCode
Table: Users
Table: Transaction
Leetcode Bank (LCB) helps its coders in making virtual payments. Our bank records all transactions in the table Transaction, we want to find out the current balance of all users and check wheter they have breached their credit limit (If their current credit is less than 0).
Write an SQL query to report.
user_iduser_namecredit, current balance after performing transactions.credit_limit_breached, check credit_limit ("Yes" or "No") Return the result table in any order.
The query result format is in the following example.
Solution
1565. Unique Orders and Customers Per Month | Easy | 🔒 LeetCode
Table: Orders
Write an SQL query to find the number of unique orders and the number of unique users with invoices > $20 for each different month.
Return the result table sorted in any order.
The query result format is in the following example:
Solution
1571. Warehouse Manager | Easy | 🔒 LeetCode
Table: Warehouse
Table: Products
Write an SQL query to report, How much cubic feet of volume does the inventory occupy in each warehouse.
- warehouse_name
- volume
Return the result table in any order.
The query result format is in the following example.
Solution
1581. Customer Who Visited but Did Not Make Any Transactions | Easy | 🔒 LeetCode
Table: Visits
Table: Transactions
Write an SQL query to find the IDs of the users who visited without making any transactions and the number of times they made these types of visits.
Return the result table sorted in any orders.
The query result format is in the following example:
Solution
1587. Bank Account Summary II | Easy | 🔒 LeetCode
Table: Users
Table: Transactions
Write an SQL query to report the name and balance of users with a balance higher than 10000. The balance of an account is equal to the sum of the amounts of all transactions involving that account.
Return the result table in any order.
The query result format is in the following example.
Solution
1596. The Most Frequently Ordered Products for Each Customer | Medium | 🔒 LeetCode
Table: Customers
Table: Orders
Table: Products
Write an SQL query to find the most frequently ordered product(s) for each customer.
The result table should have the product_id and product_name for each customer_id who ordered at least one order. Return the result table in any order.
The query result format is in the following example:
Solution
1607. Sellers With No Sales | Easy | 🔒 LeetCode
Table: Customer
Table: Orders
Table: Seller
Write an SQL query to report the names of all sellers who did not make any sales in 2020.
Return the result table ordered by seller_name in ascending order.
The query result format is in the following example.
Solution
1613. Find the Missing IDs | Medium | 🔒 LeetCode
Table: Customers
Write an SQL query to find the missing customer IDs. The missing IDs are ones that are not in the Customers table but are in the range between 1 and the maximum customer_id present in the table.
Notice that the maximum customer_id will not exceed 100.
Return the result table ordered by ids in ascending order.
The query result format is in the following example.
Solution
1623. All Valid Triplets That Can Represent a Country | Easy | 🔒 LeetCode
Table: SchoolA
Table: SchoolB
Table: SchoolC
There is a country with three schools, where each student is enrolled in exactly one school. The country is joining a competition and wants to select one student from each school to represent the country such that:
member_Ais selected fromSchoolA,member_Bis selected fromSchoolB,member_Cis selected fromSchoolC, and The selected students' names and IDs are pairwise distinct (i.e. no two students share the same name, and no two students share the same ID). Write an SQL query to find all the possible triplets representing the country under the given constraints.
Return the result table in any order.
The query result format is in the following example.
Solution
1633. Percentage of Users Attended a Contest | Easy | 🔒 LeetCode
Table: Users
Table: Register
Write an SQL query to find the percentage of the users registered in each contest rounded to two decimals.
Return the result table ordered by percentage in descending order. In case of a tie, order it by contest_id in ascending order.
The query result format is in the following example.
Solution
1635. Hopper Company Queries I | Hard | 🔒 LeetCode
Table: Drivers
Table: Rides
Table: AcceptedRides
Write an SQL query to report the following statistics for each month of 2020:
The number of drivers currently with the Hopper company by the end of the month (active_drivers). The number of accepted rides in that month (accepted_rides). Return the result table ordered by month in ascending order, where month is the month's number (January is 1, February is 2, etc.).
The query result format is in the following example.
Solution
1645. Hopper Company Queries II | Hard | 🔒 LeetCode
Table: Drivers
Table: Rides
Table: AcceptedRides
Write an SQL query to report the percentage of working drivers (working_percentage) for each month of 2020 where:
Note that if the number of available drivers during a month is zero, we consider the working_percentage to be 0.
Return the result table ordered by month in ascending order, where month is the month's number (January is 1, February is 2, etc.). Round working_percentage to the nearest 2 decimal places.
The query result format is in the following example.
Solution
1651. Hopper Company Queries III | Hard | 🔒 LeetCode
Table: Drivers
Table: Rides
Table: AcceptedRides
Write an SQL query to compute the average_ride_distance and average_ride_duration of every 3-month window starting from January - March 2020 to October - December 2020. Round average_ride_distance and average_ride_duration to the nearest two decimal places.
The average_ride_distance is calculated by summing up the total ride_distance values from the three months and dividing it by 3. The average_ride_duration is calculated in a similar way.
Return the result table ordered by month in ascending order, where month is the starting month's number (January is 1, February is 2, etc.).
The query result format is in the following example.
Solution
1661. Average Time of Process per Machine | Easy | 🔒 LeetCode
Table: Activity
There is a factory website that has several machines each running the same number of processes. Write an SQL query to find the average time each machine takes to complete a process.
The time to complete a process is the 'end' timestamp minus the 'start' timestamp. The average time is calculated by the total time to complete every process on the machine divided by the number of processes that were run.
The resulting table should have the machine_id along with the average time as processing_time, which should be rounded to 3 decimal places.
The query result format is in the following example:
Solution
1667. Fix Names in a Table | Easy | 🔒 LeetCode
Table: Users
Write an SQL query to fix the names so that only the first character is uppercase and the rest are lowercase.
Return the result table ordered by user_id.
The query result format is in the following example:
Solution
1677. Product's Worth Over Invoices | Easy | 🔒 LeetCode
Table: Product
Table: Invoice
Write an SQL query that will, for all products, return each product name with total amount due, paid, canceled, and refunded across all invoices.
Return the result table ordered by product_name.
The query result format is in the following example:
Solution
1683. Invalid Tweets | Easy | 🔒 LeetCode
Table: Tweets
Write an SQL query to find the IDs of the invalid tweets. The tweet is invalid if the number of characters used in the content of the tweet is strictly greater than 15.
Return the result table in any order.
The query result format is in the following example:
Solution
1693. Daily Leads and Partners | Easy | 🔒 LeetCode
Table: DailySales
Write an SQL query that will, for each date_id and make_name, return the number of distinct lead_id's and distinct partner_id's.
Return the result table in any order.
The query result format is in the following example:
Solution
1699. Number of Calls Between Two Persons | Medium | 🔒 LeetCode
Table: Calls
Write an SQL query to report the number of calls and the total call duration between each pair of distinct persons (person1, person2) where person1 < person2.
Return the result table in any order.
The query result format is in the following example:
Solution
1709. Biggest Window Between Visits | Medium | 🔒 LeetCode
Table: UserVisits
Assume today's date is '2021-1-1'.
Write an SQL query that will, for each user_id, find out the largest window of days between each visit and the one right after it (or today if you are considering the last visit).
Return the result table ordered by user_id.
The query result format is in the following example:
Solution
1715. Count Apples and Oranges | Medium | 🔒 LeetCode
Table: Boxes
Table: Chests
Write an SQL query to count the number of apples and oranges in all the boxes. If a box contains a chest, you should also include the number of apples and oranges it has.
Return the result table in any order.
The query result format is in the following example:
Solution
1729. Find Followers Count | Easy | 🔒 LeetCode
Table: Followers
Write an SQL query that will, for each user, return the number of followers.
Return the result table ordered by user_id.
The query result format is in the following example:
Solution
1731. The Number of Employees Which Report to Each Employee | Easy | 🔒 LeetCode
Table: Employees
For this problem, we will consider a manager an employee who has at least 1 other employee reporting to them.
Write an SQL query to report the ids and the names of all managers, the number of employees who report directly to them, and the average age of the reports rounded to the nearest integer.
Return the result table ordered by employee_id.
The query result format is in the following example:
Solution
1741. Find Total Time Spent by Each Employee | Easy | 🔒 LeetCode
Table: Employees
Write an SQL query to calculate the total time in minutes spent by each employee on each day at the office. Note that within one day, an employee can enter and leave more than once.
Return the result table in any order.
The query result format is in the following example:
Solution
1747. Leetflex Banned Accounts | Medium | 🔒 LeetCode
Table: LogInfo
Write an SQL query to find the account_id of the accounts that should be banned from Leetflex. An account should be banned if it was logged in at some moment from two different IP addresses.
Return the result table in any order.
The query result format is in the following example:
Solution
1757. Recyclable and Low Fat Products | Easy | 🔒 LeetCode
Table: Products
Write an SQL query to find the ids of products that are both low fat and recyclable.
Return the result table in any order.
The query result format is in the following example:
Solution
1767. Find the Subtasks That Did Not Execute | Hard | 🔒 LeetCode
Table: Tasks
Table: Executed
Write an SQL query to report the IDs of the missing subtasks for each task_id.
Return the result table in any order.
The query result format is in the following example:
Solution
1777. Product's Price for Each Store | Easy | 🔒 LeetCode
Table: Products
Write an SQL query to find the price of each product in each store.
Return the result table in any order.
The query result format is in the following example:
Solution
1783. Grand Slam Titles | Medium | 🔒 LeetCode
Table: Players
Table: Championships
Write an SQL query to report the number of grand slam tournaments won by each player. Do not include the players who did not win any tournament.
Return the result table in any order.
The query result format is in the following example:
Solution
1789. Primary Department for Each Employee | Easy | 🔒 LeetCode
Table: Employee
Employees can belong to multiple departments. When the employee joins other departments, they need to decide which department is their primary department. Note that when an employee belongs to only one department, their primary column is 'N'.
Write an SQL query to report all the employees with their primary department. For employees who belong to one department, report their only department.
Return the result table in any order.
The query result format is in the following example.